Case Study: Is Spurious Correlations the reason why Neural Networks fail on unseen data?
Problems caused by spurious correlations and data-centric approach to deal with them and train Robust Models.

Robust Deep Learning
This article is a part of series that address Robust Deep Learning. We have talked about model generalization, robustness invariance and causality in details in previous articles. In this article we practically how Data Augmentations and Domain Randomization help ensure model robustness. To best appreciate the content read these articles:
- Invariance, Causality, and Robust Deep Learning
- Domain Randomization: future of robust modeling
- Rethinking Data Augmentations: A Causal Perspective
- Systematic Approach to Robust Deep Learning
In this tutorial you will learn the following:
- Understand spurious correlations and how they occur in data
- Understand how and why neural networks fail on new data due to spurious correlations
- Learn data-centric strategies (Domain Randomization & Data Augmentation) to minimize these failures
It is a wild world out there! Whenever you sample a portion of it to collect data for you machine learning task, their is a healthy chance that some spurious correlations will creep into it. What is a spurious correlation?
In statistics, a spurious relationship or spurious correlation is a mathematical relationship in which two or more events or variables are associated but not causally related, due to either coincidence or the presence of a certain third, unseen factor. ~ Wikipedia
When you are training a model, it is implicitly implied that you want it to learn from causal features so that it learns the true data generation process. Association of the label to non causal features is not guaranteed to hold in a different sample, affecting the reliability of you model. Neural networks are glorified pattern matching machines without any real intelligence, so the data that is fed into it needs to carefully engineered. Neural networks only know to learn an input output mapping that minimizes the loss on training data, it does not have cognition to build human like insights. We will conduct an experiment around this but first let us look at an example of spurious correlation.
Cow Grass Example
Deep learning network trained for image classification on outdoor datasets can learn from cues in the image background. They can utilize associations between the background and the class label to build decision rules which are undesirable. One such example is of cow and grass, cows are more likely to be seen in grass rather than on a beach. As neural network ingests the data with this association if will tend to learn grass as vital feature for cow classification, if it results in a lower loss (which is all a neural network cares for!)

Neural networks successfully classified cows in familiar grassy backgrounds but failed to do so for unfamiliar background like a beach¹. Now we might think that grass is not a totally informative feature, and cows are indeed more likely to be present alongside the grass. But is grass a causal feature for cow classification? If you aim to build a classifier that can classify cows from Irish grasslands to streets of India, grass wont help.
Another property of a spurious correlation is that it can vary across different domains (different data distributions). The association strength between grass and cow will depend on the geographic location data is taken from. If the data is taken from urban India, where cows roam in streets, this association is going to be a lot weaker. Where, as this association is going to be very strong if data comes from an Himalayan herding community.
Let us discuss some important concepts before we jump to our experiment:
Independent and Identically Distributed (IID)
Two datasets are referred to as IID if they are randomly sampled from the same data generation process. In machine learning, it is a standard practice to randomly split the collected data into train and test sets, which in this particular scenario are IID(independent and identically distributed).
Out of Distribution (OOD) Datasets
A dataset is considered out of distribution if it is sampled from a different data distribution. In machine learning OOD of interest are those where causal relationships are similar to training data but other properties might change. In cow-grass example a dataset collected in urban India would be OOD for data collected in Himalayan grassland, since the landscape would change but concept of cow would be similar.
Underspecification
An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. ~ Underspecification Presents Challenges for Credibility in Modern Machine Learning
Evaluation metrics on IID dataset (test set)are the most commonly used criteria to measure performance of the network. Underspecificaiton is condition where ML pipeline can produce many models with equally good performance on IID but with drastically different OOD performances. We will also investigate the effect of spurious correlations on underspecification in our experiments.
Data
We will create a simple regression data set where the output has linear relationship to the causal features:
Y = x1 + 2*x2 + 3 + N(0,1)
X3 = Y + N(0,3)Where ,
- X1 is a causal feature with coefficient=1
- X2 is a casual feature with coefficient=2
- X3 has a strong spurious correlation with y
We will create three datasets.
# training data
X,y = get_data(n=5000, spurious_correlation_factor=0.2)# iid data with same distribution as training
iid_X,iid_y = get_data(n=5000, spurious_correlation_factor=0.2)## ood data with a different correlation factor to X3
ood_X,ood_y = get_data(n=5000, spurious_correlation_factor=0.1)
Training data: we create 5k data points with correlation factor of 5. In analogy of cow-grass example it can be thought of as country with a stronger association strength between grass and cow occurrences.
IID data: we create 5k data points of similarly distributed data with same correlation factor. This would be the usual validation set in machine learning.
OOD data: we create 5k data points with correlation factor of 10. OOD data is similar to training data in terms of causal features but has a spurious correlation of different strength. In analogy to cow-grass example it can be though of as a different country with the association being half as strong.
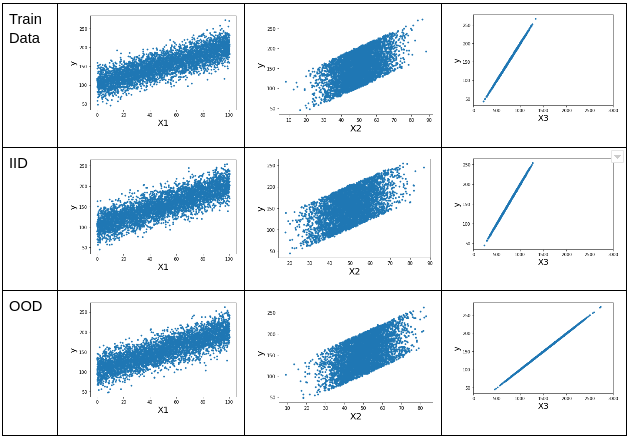
Model
For simplicity and interpretability, we will use a simple Perceptron model first without a non-linearity. Later on we will reproduce the results with Multi-layerd Perceptron.
Training
The training settings used for all experiments are given below.
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3, betas=(0.9, 0.999), eps=1e-08)scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)criterion = nn.MSELoss()NUM_EPOCHS = 30
We use Root Mean Square Error (RMSE) for evaluation of all models.
Results

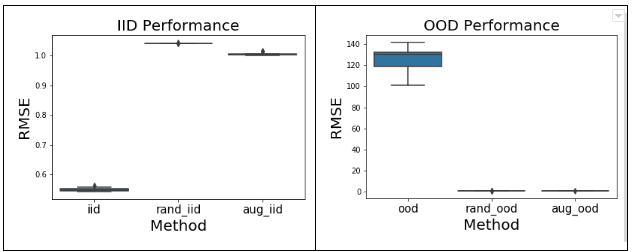
Here we can see that the third coefficient is not zero as it should have been, since x3 is a spurious correlation with unstable association to Y. Hence, the model has learned x3 as a strong predictive feature and will not generalize well to datasets with different distribution of x3.

We see that the models fail spectacularly on ood dataset when strength of spurious correlation changes. We repeat this experiment multiple times for more certainty in results and to test for underspecification (defined above).

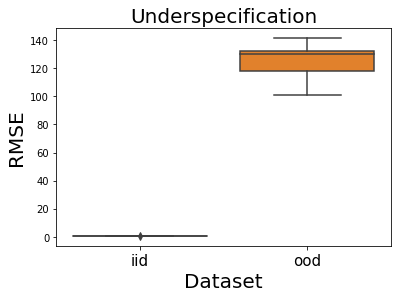
As we can see above, underspecification is indeed observed ! Multiple runs of the training with the same training dataset, only differing in random seeds produce models which can differ in ood performance even though they are equally good in iid performance. This can be observed in the difference in standard deviations of iid and ood RMSe.
Potential Solutions
One way to tackle problems related to bad generalization and underspecification is to build models that are invariant to all non causal properties of the data. If a model sees the data where a particular property changes frequently and substantially without impacting the output, it will develop invariance to that property. Hence, ideal scenario would be to totally randomize all the con-causal properties of the dataset. Two major ways of achieving this would be:
- Domain Randomization: Collect data randomly from many different domains. In analogy to cow-grass example if we collected datasets from different countries where association strength changes, our model will learn to build invariance to grassy background.
- Use data augmentation to randomize this property. Data augmentations for building invariance are transforms that randomly change a certain property of the dataset without changing the output.
Note that we can only perform domain randomization or data augmentation for a property for which we are sure not to be causal. This can be tricky, but their are always some obvious ones. In cow-grass analogy we can identify background landscape as a non-causal property which needs to be randomized.
For how to select the appropriate properties and randomization parameters read:
Domain Randomization
Randomizing the association strength is equivalent to randomly sampling data from many domains. In cow-grass analogy it would be sampling from many countries which vary in strength of this association. We perform the same training and evaluation for this data, as done before.

Here we can see that weights are lot closer to the true data generation process. Furthermore, model appears to be invariant to feature X3 as evident from a minute coefficient. Hence, we can expect them to generalize well to unseen data distributions (OOD).

As expected this model generalizes well to out of distribution (OOD) data giving good results. Now lets look at results from 10 runs.

As the model is learning from causal features it is evident that it is producing good results. Furthermore, it is interesting to note that building invariance to non-causal properties diminishes underspecification! This is an important conclusion, we can use underspecification as an auxiliary evaluation criteria along with performance on OOD.
Data Augmentation
We modify the training function as shown below:
Line 15 above is responsible for data augmentation, it adds random noise to the X3 feature during each batch. This is similar to standard data augmentation strategies that is widely used, with all major platforms providing support for it. It is similar to random translation or random rotation augmentations commonly used in computer vision.

Data augmentation on X3 produces the desired result of building invariance to it as seen from its coefficient. This makes the other weights closer to data generation process.

As expected, the model produces low errors on ood data.

Similar to results with domain randomization, we see better generalization to ood dataset and diminished effect of underspecification.
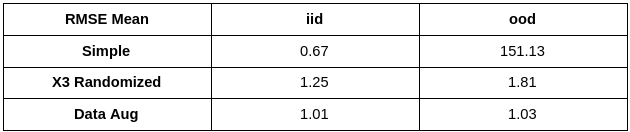
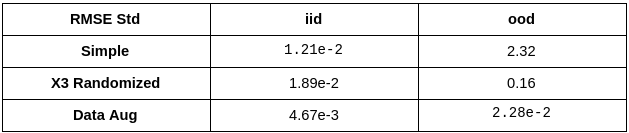
Summary of Results
We put together all results for easier comparison.
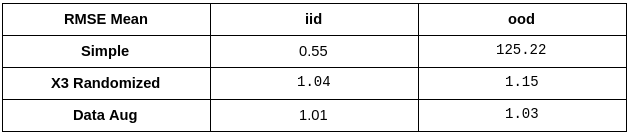
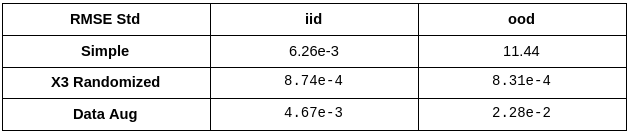
Having summarized the results, lets reflect on a fundamentally important aspect of this problem. In a normal ML project you collect all the data you can and then split it into training and test sets, hence test set is an iid. It is a standard practice to use test set metrics as a measure of model performance. They are also used for architecture search and hyper-parameter tuning.
Now if you look above at how iid performance varies across experiments, you will find it was the best in simple experiment. This is because relying on a spurious correlation can sometimes make the task easier to solve. Furthermore, with iid evaluation alone you would never know if anything was wrong. Hence, ood evaluations become important evaluation tests for the model.
Replicating Results with MLP
As above results were produced for simple Perceptron model, we repeat the exact same experiment on Multi Layered Perceptron to see if the same trends are observed.
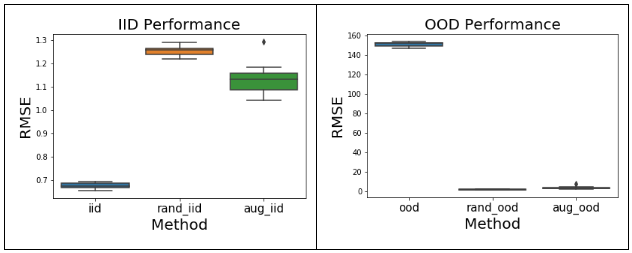
As we can see above, spurious correlation are equally detrimental to deeper networks and they also lead to underspecification. Randomization of non-causal property either through domain randomization or data augmentation can force network to be invariant to that property, hence encouraging the network to rely on causal properties. This increases model robustness and it generalizes well to unseen datasets.
Conclusions
- Datasets are biased: spurious correlations can creep into your data due to various reasons and this needs to be dealt with consciously.
- Neural Networks are prone to data failures: Dataset biases can seriously derail the neural network from intended solution, which can result in spectacular failures when they are applied to a different distribution.
- OOD Evaluations are necessary: when ever you have access to OOD dataset it is good practice to measure performance on it, since iid performance alone is not a good measure of model credibility.
- Data Augmentation is your friend: data augmentation has been widely celebrated for ability to create more data from existing data. But as we have seen, what it actually does is to randomize a known non-causal property to ensure that network is invariant to this property.
- Representational Data: Rather than only focusing on volume we should try to get as much variation in data as possible, so that most non-causal properties are randomized naturally.
References
[1] Beery, S., Van Horn, G. & Perona, P. Recognition in terra incognita. InProceedingsof the European Conference on Computer Vision, 456–473 (2018).