Domain Randomization: future of robust modeling
Learn how to leverage this tool to unlock the true potential of synthetic data for Machine Learning!

Domain Randomization
Domain randomization is a systematic approach to data generation process that aims to enhance generalization of the machine learning algorithms to new environments.
Domain randomization is an approach where one tries to find a representation that generalizes across different environments, called domains. ~ Intervention Design for Effective Sim2Real Transfer
The purpose of domain randomization is to provide enough simulated variability at training time such that attest time the model is able to generalize to real-world data. ~ Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World
What are Domains: A causal perspective
A domain could denote different measuring circumstances such as locations, times, experimental conditions, contexts at the time of data collection.
This input image is a product of a causal mechanism (the data generation process) and contains other information (domain attributes) that has no fundamental relationship to the concept of cow. We will try to paint a causal perspective of this phenomenon.

The above image (right) shows the Structural Causal Model (SCM) of the data generation process. Corresponding Directed Acyclic Graph(DAG) is shown on left, where the grey node denotes the observed variable and a white node denotes a latent (unobserved) variable. Here:
d -> the domainy -> class labelhd -> Domain Attributes: high-level features like color and background caused by domainhy -> Causal Features:high-level features like shape and texture caused by object class
Domain attributes are features with no causal link to the label. Causal features have a direct causal link to the label.
Let us list some of the domain attributes and causal features in this image.
Domain Attributes:
- Background landscape: colors, grassy texture and edges in background
- Brightness/Contrast: lighting conditions and camera settings
- Sharpness and other image attributes
- Perspective: relative pose of cow and camera
Causal Features:
- Shape of cow: nose, ears eyes and other shapes
- Texture of cow: they furry texture that spans cow body
Domain Randomization: As the name implies domain randomization means randomly sampling each data samples domain attributes from a predefined space of domain attributes while creating dataset.
That was really simple! Domain randomization has been a successful tool which has enabled models trained on synthetic/simulation data to work well on real datasets. In the coming sections, we will see why it works so well.
Why does Domain Randomization work?
I found two different narratives in the literature about why domain randomization works. We will talk about both of them.
1- Exploiting High Variance
This view builds upon the fact that neural networks are low bias high variance machines and can be given enough capacity they can successfully find a mapping from input to data for all seen distributions of data. If we sample domain attributes from wide distributions, the model will see a huge variety of domains during training, and real data would appear to be just another variation. So we need to design the domain attribute distributions with high variance so that it overlaps with the real world.
As we will see in the section below, with this view the approach towards designing the distributions of domain attributes is to aim for an overlap with real datasets. Hence, the more real the data appears to be, the better it would perform on the target domain(real data).
This view aims to create an overlap with real data, hence the variance of domain attributes is increased with the hope that they will somehow overlap the real distribution.2- Building Domain Invariance
This view aims to train models that are invariant to domain attributes and learns to ignore them while making a prediction. This is a way more interesting take at explaining domain randomization (I might be biased)! Let us discuss what it means.
Bias in Datasets
Let's look at the cow image again. Such images can be a normal input for a neural network designed for object classification. The neural network sees this image during training and is expected to learn the concept of cow from it so that it can successfully classify cows when it sees them. The images observed by the neural network during training has both domain attributes and causal features. A correct neural network will only learn from causal features and will be totally invariant to all domain attributes. Humans visual system is tuned to see objects but the neural network is just observing arrays of pixel values and tries to find any relationship it can between the label and input.
We know that cows are normally seen in green backgrounds, and neural networks tend to learn this correlation between background (domain attribute) and cows as shown in this study. Such networks fail to classify cows in non-green backgrounds! Such relationships between domain attributes and labels are known as spurious correlations, they pose a great threat to model’s generalization to new environments. For more detail about spurious correlations read: Neural Networks fail on data with Spurious Correlation
Domain Randomization: breaking the spurious correlation
We want the networks to learn from causal features because they hold true across different environments. If the Neural network is invariant to all the domain properties, we can assume that it is learning from causal features and so it will be robust to new domains.
Now, look at domain randomization from this perspective. All the domain attributes are sampled randomly from the attribute space. A random variable with enough samples can not have a correlation with anything, hence the dataset will not have any spurious correlations. Consequently, neural network will rely on causal attributes.
In this view, the overlap between simulated and target data is not essential. Random sampling is the focus of this approach.
Perturbations to the environment do not have to be realistic, but merely show variation along dimensions that also vary in the real world ~ Intervention Design for Effective Sim2Real Transfer
For detailed understanding read Invariance, Causality and Robust Deeplearning.
Another important aspect is the variance of the domain attribute. A domain attributed randomly sampled from a narrow low variance distribution can still be a hurdle to invariance building in networks. A random variable with a small variance or constant value, both can break spurious correlations. But neural network can still overfit them and fail to develop invariance to this domain attribute, performing poorly when its distribution changes. This fact is under emphasized in literature, hence we study this phenomenon in a separate post: Striking failure of Neural Networks due to conditioning on totally irrelevant properties of data
This view aims does not pursue realism, it strives to build invariance in models. This is done by randomizing the domain attributes ( to kill spurious correlations) and enhancing its variance (to avoid over overfitting).Choosing the domain attributes
We can define and intervene on specific variables we know can vary across simulation and real settings ~ Intervention Design for Effective Sim2Real Transfer
Choosing the right domain attributes is very important, but is dealt with casually in the literature. Machine Learning experts, synthetic data experts and domain experts must sit together and try to build an exhaustive list of all the domain attributes(non causal features), which can change from domain to domain. The more exhaustive this list is, the better the generalization of the model trained on this data will be.
In the post, Systematic Approach to Robust Deep Learning, I look in details at how the domain attributes should be listed for a given computer vision task.
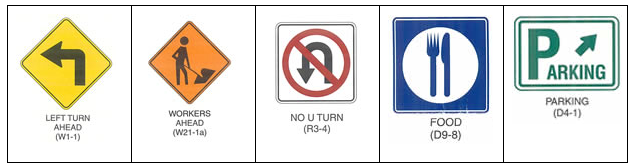
Let's look at an example task of US road sign classification. For this task we can say that:
- System should be invariant to domain attributes: translation, scale, brightness, contrast, saturation, cropping, blur, image quality, weather conditions, background
- System should be invariant to small perturbations in features: rotation, color and perspective.
Choosing the distribution of domain attributes
Choosing the range/variance of domain attributes is very important.
Selecting which aspects of the simulation to vary is often left to human design. However,negative transfer (poor performance in the real world) can arise perturbing irrelevant factors, or even varying the right factors by too much or by too little. ~ Intervention Design for Effective Sim2Real Transfer
Having slightly different motivations to domain randomization, people can have different approaches to domain attributes. We will talk about two major approaches:
Chasing Realism: Some prefer to pursue realism and try to bring domain attributes as close to real data as possible.
Building Domain Invariance: Others prefer to build invariance to domain attributes, and focus on randomization and variance rather than realism.
Chasing Realism
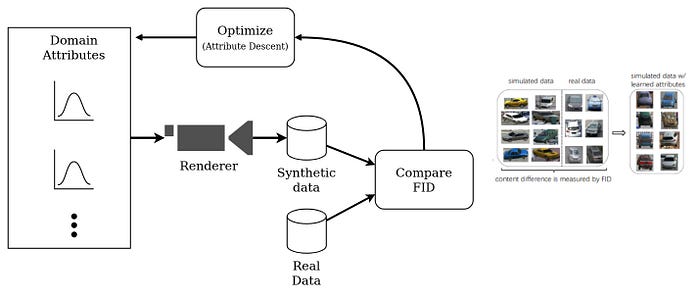
Using the study, Simulating Content Consistent Vehicle Datasets with Attribute Descent, as an example. They intend to create a synthetic single vehicle image dataset, which is as close as possible to the real target dataset. They identify the following domain attributes for randomization:
- Vehicle orientation
- Camera height
- Distance to Camera
- Light direction
- Light Intensity
During simulation all domain attributes are randomly variable sampled from the Gaussian mixture distributions. The parameters (mean and standard deviations) of these gaussians are optimized to best simulate target dataset. Fréchet inception distance is used as the cost function for their proposed optimization, and they call this method attribute descent.
We speculate that the means of the Gaussian distributions or components are more important than the standard deviations because means reflect how the majority of the vehicles look. Although our method has the ability to handle variances, this would significantly increase the search space. As such, we pre-define the values of standard deviations and only optimize the means of all the Gaussians. ~ Simulating Content Consistent Vehicle Datasets with Attribute Descent
Random sampling of domain attributes will ensure that spurious correlations are not present. But such methods can suffer from problems caused by low variance in domain attributes. Hence, models trained on these datasets might perform well on target dataset but they are not expected to generalize well to datasets where domain attributes have different distributions.
In cases where optimizing for domain attributes is hard, emphasis is given on variance in domain attributes with hope of achieving maximum overlap with real distributions.
With enough variability in the simulator, the real world may appear to the model as just another variation. ~ Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World
Building Domain Invariance
This approach emphasizes on identifying domain attributes and building domain invariance to it. This exercise relies mostly on causal reasoning around the problem rather than looking at statistics in real distribution and trying to match it. It drives motivation from knowledge, that a system inherently has some invariances and modelling them results in robust models which can work well in any distribution of domain attributes. For a detailed understanding of these concepts read: Invariance, Causality and Robust Deeplearning

We can define and intervene on specific variables we know can vary across simulation and real settings, e.g. table top color and texture, background, and/or mass of objects. Further, these interventions don’t need to be “realistic”. We can use a texture never seen at evaluation time (image above). ~ Intervention Design for Effective Sim2Real Transfer
So in this approach we usually prefer Uniform Domain Randomization. We specify the range of each domain attribute and then sample from this uniform distribution randomly for each image/sample. In causes when this domain attribute is not a continuous variable we attempt to gather a large number of discreet values and sample randomly from it. These ranges can be specified by using causal reasoning. Let's look at the sign example again.
Background: Background is a classic domain attribute so we need to randomize it fully. One way to do so would be to gather a wide array of diverse images and textures (not necessarily real), and select one randomly for each image. The idea would be to randomly vary it so that there is no correlation between it and label, and the model learns invariance to it.
Rotation: In the sign classification task, rotation of 90 degrees can change the meaning of signage, thus it has causal links to the label and so it is not a domain attribute like brightness and contrast. But it can be expected to see small rotations of about 10,20 degrees while capturing images in the wild. So we can consider small perturbations in rotation as a domain attribute.
Color: Similarly, signs are color coded so color is not a domain attribute in the full sense. But small perturbations which merely change shade/temperature of color can be called domain attributes. It is important to identify all domain attributes that you want to randomize and their ranges upfront.
Blur: This is a domain attribute that can vary with speed of vehicle, focusing of camera etc. Its bounds can be chosen based on human perception. It is interesting to note that we are not setting maximum blur to match the most blurry images in our training set, but we are using reasoning about what the maximum blur encountered in any circumstances(domain) could be. So rather than limiting to what you currently see in data, it is desirable to range over all possible domains.
Domain Randomization vs Data Augmentation
Data Augmentation through random perturbations is similar to domain randomization, since it is used to randomize a domain attribute. While domain randomization is restrictive because it is only possible in the data gathering stage, data augmentation is convenient because it can be done as a post data acquisition step. But some attributes such as foreground textures, backgrounds and occlusions are difficult to randomize with data augmentations.
Practical Domain Randomization: Synthetic Data
Domain Randomization can only be applied at the data gathering stage and requires you to have control over the data generation process. So practically, it is only applicable to synthetic/simulated data in most scenarios. To conclude the post let us summarize the benefits of domain randomized synthetic data.
- Volume: Theoretically infinite amount of data is available, so it is especially beneficial for data constrained problems.
- Spurious Correlations: Randomization of domain attributes ensure that no spurious correlations exist in data.
- Variation: We can create datasets with large variation in domain attributes.
- Rare Things: It is very hard to get substantial data for some rare events or classes in the real world. There are no such barriers in synthetic data.
- You can export the metadata along with the dataset, which is useful for stratified testing
Where to go from here:
Develop a better understanding of the link between causality invariance and robustness: Invariance, Causality and Robust Deeplearning
Learn how to use domain randomization and data-augmentation in a systematic design by invariance approach for robust modelling: Systematic Approach to Robust Deep Learning
Start exploring Unity Perception Package for visual synthetic Data.
